
Want to share your content on R-bloggers? click here if you have a blog, or here if you don’t.
I wrote a
post last year looking at how to employ tools in LangChain to have
GPT-3.5 Turbo access information on the web, outside of its training
data.
The purpose of the present post is to revisit this post, improving
the poor performance I saw there through refactoring and prompt
engineering.
Background
The motivating example is again using large language models (LLMs) to
help me calculate features for my Oscar model.
Specifically: How many films did the director of a Best Picture nominee
direct before the nominated film?
Mistakes I Made Last Time
In the previous post, I found pretty poor performance. Some of this
is due to the studio system in old Hollywood: Directors of films before
about 1970ish could have ludicrously large bodies of work due to the
studio system and due to shorts, documentaries, or films made for WWII.
This underscores the importance of domain expertise in data science.
Even looking at performance in the more contemporary era, the
performance was still poor (I will get into this more below). So, I made
a few changes before trying it again this year.
Change 1: This time around, I decided to only look
at films nominated after 1969. This reflects a qualitative shift in the
underlying data generation mechanism—there was no more studio system,
and the directors that were prolific under that system are no longer
having films nominated for Best Picture by 1970.
Change 2: I was using GPT-3.5 Turbo inside of a
LangChain agent that was equipped with the Wikipedia API and a
calculator. The issue here is that I used defaults for the Wikipedia
tool, which defaults to only allowing the first
4,000 characters from the page. Given that the “filmography” section
of directors’ pages occurs near the bottom of the page, this was never
getting read into the LLM. Even though it appears that they have
increased the max character length, I could not get it to read in
more this time around. So, I ditched the LangChain approach…
Change 3: …and replaced it with Perplexity AI. They
have built a “conversational
search engine”. The basic idea is that they use existing
foundational models and give them the tools to search the web for
real-time information to answer your query. This is more or less the
agent I was trying to make myself with LangChain… except it performs
much better, and it can access sources beyond Wikipedia. (The payload
actually has a citations section where you can see the hyperlinks it
used to find the information.) With there being no free lunch, however,
it is more expensive. Even if you use an open source foundational model,
Perplexity charges you a premium for using their agent on top of it that
is searching the web. Even with all the prompting I gave it, this entire
blog post still only cost me a few bucks, with the final dataset being
$1.32.
Change 4: Refactoring my prompt through prompt
engineering. Let’s look at the prompt I made in the original blog
post:
("system", """You are a helpful research assistant, and your job is to
retrieve information about movies and movie directors. Think
through the questions you are asked step-by-step."""),
("human", """How many feature films did the director of the {year} movie
{name} direct before they made {name}? First, find who
directed {name}. Then, look at their filmography. Find all the
feature-length movies they directed before {name}. Only
consider movies that were released. Lastly, count up how many
movies this is. Think step-by-step and write them down. When
you have an answer, say, 'The number is: ' and give the
answer."""),
In the system message, we see I tried to use chain-of-thought prompting.
The idea here was I told it to think “step-by-step,” and then I
explicitly gave it steps to take in the human part of the
prompt. As I’ve read more about prompt engineering (such as this book and this book), I realize
that what I was doing here was confusing two concepts. One of the basic
principles is to break down tasks into modular parts and divide
labor. I thought I was giving the model a way to reason
step-by-step… but what I should have realized is I was giving it way too
many tasks and intermediate steps to do in one prompt. I’ll get into how
I improved this dogshit prompt below.
The Current Approach
As mentioned above, I’m now using the Perplexity API with a rewritten
prompt. First, I use the OpenAI module in Python to access Perplexity,
which will be using the llama-3.1-sonar-large-128k-online
model under the hood. I define a Python function, which I will be
calling from R using {reticulate}. The function is:
from openai import OpenAI API_KEY="" model="llama-3.1-sonar-large-128k-online" client = OpenAI(api_key=API_KEY, base_url="https://api.perplexity.ai") def get_films(director): messages = [ { "role": "system", "content": """ You are a detailed research assistant helping the user find the names of movies. The user will give you a name of a director, and it is your job to find the name and year of every feature-length movie this person has ever directed. Finding an accurate list of these movies is important because the information will be employed by the user in a project where having an accurate list of films is vital. Do not list TV movies, as these are not feature-length movies. Do not list TV episodes, as these are not feature-length movies. Do not list mini-series, as these are not feature-length movies. Do not list music videos, as these are not feature-length movies. Do not list short films, as these are not feature-length movies. Many of these people may have also acted in or wrote or produced films—do not list these films unless they also directed the film. You should respond in a very specific format: A list where two greater-than signs (>>) begin each line. You should say the name of the film, then include two tildes (~~), then say the year it was released. Include no other text before or after the list; do not give any commentary. Only list the name and year of every feature-length movie this person has ever directed. """, }, { "role": "user", "content": "Rian Johnson" }, { "role": "assistant", "content": """ >> Brick ~~ 2005 >> The Brothers Bloom ~~ 2008 >> Looper ~~ 2012 >> Star Wars: The Last Jedi ~~ 2017 >> Knives Out ~~ 2019 >> Glass Onion ~~ 2022 """ }, { "role": "user", "content": "John Krasinski" }, { "role": "assistant", "content": """ >> Brief Interviews with Hideous Men ~~ 2009 >> The Hollars ~~ 2016 >> A Quiet Place ~~ 2018 >> A Quiet Place Part II ~~ 2020 >> IF ~~ 2024 """ }, { "role": "user", "content": director }, ] response = client.chat.completions.create( model=model, messages=messages, temperature=0 ) return(response.choices[0].message.content)
Let’s look at the prompt, one piece at a time. First, I take all of
the static information that will be the same from one call to another
and put that in the system content. The first paragraph
defines what the assistant is and why, as giving reasons behind
actions can help improve performance (pg. 91). The second
paragraph tells the model what not to list. Although one of the basic
principles of prompting is to tell it what to do instead of
what telling it NOT to do, I couldn’t find a better way of
telling the model what it should exclude from the list. My hope in being
repetitive here was that the tokens representing music videos, shorts,
mini-series, etc., would be close enough to the word “not,” and I gave
it a reason for excluding each of them. I give it a very specific format
to respond with. Why? I noticed that so many special characters are used
in film names. Markdown likes asterisks, and LLMs like Markdown.
Problem! Movie titles can be italicized in Markdown using asterisks, and
film names can have asterisks in them (e.g., M*A*S*H). Hence
the double >> and the double ~~ to break up the list. I tell it to
give no other commentary, and then I “sandwich” the prompt by reminding
the model of its primary objective (pg. 125).
I then employ few-shot learning to show examples of proper
user and assistant calls to drive home the
format and what to (and not to) include. I chose these two directors for
very specific reasons. Rian Johnson has directed short films, TV
episodes (such as a few notable ones from Breaking Bad), music
videos (including “oh baby” by LCD
Soundsystem), and a commercial. My example only lists feature films.
I also included John Krasinski, as he is primarily known as an actor
(that is, Jim from The Office). In the actual Academy Award
data, there are folks like Clint Eastwood and George Clooney who are
primarily known as actors but show up as directors. Lastly, I chose
these two because they do not appear in the dataset of directors of
films nominated for Best Picture, so there’s no ability for the model to
simply copy one of the examples.
Lastly, you’ll notice I don’t give the model a movie, ask it to find
the director, then ask it to find their filmography, then ask it to
return me the number of films before the film I gave it. That’s too
much—let’s divide labor. What I am doing is now simply asking them for
their full filmography. I can rely on data I already pulled down using
the OMDb API to get the director for each film. I can then get the
number of previously-directed films by working with the data in R.
Dividing the Labor in R
Retrieving the Data
I set up {reticulate} using a virtual environment that
is a path relative to my own Google Drive, and then I source the script
with the Python function in it. I already have the director(s) for each
film in a Google Sheet. I pull this down—and separate longer when there
are multiple directors—to get a list of individuals who directed a film
nominated for Best Picture after 1969.
I then initialize an empty string variable and fill it with the
result from the call to Perplexity in a loop.
# prep -------------------------------------------------------------------------
library(googlesheets4)
library(tidyverse)
library(reticulate)
use_virtualenv("../../../../")
source_python("ppxai.py")
gs4_auth()
2
# load director list -----------------------------------------------------------
dat <- read_sheet("") %>%
filter(year > 1969) %>%
select("director") %>%
separate_longer_delim(director, ", ") %>%
unique()
# run --------------------------------------------------------------------------
dat$films_string <- NA # initialize
for (i in seq_len(nrow(dat))) {
if ((i %% 20) == 0) cat(i, "\n")
dat$films_string[i] <- get_films(dat$director[i])
}
# write out --------------------------------------------------------------------
write_csv(dat, "directors_films.csv")
Cleaning Data
The previous script takes the raw content of the payload. I want to
reformat it into something tidier.
# prep -------------------------------------------------------------------------
library(tidyverse)
dat <- read_csv("directors_films.csv")
# parse string -----------------------------------------------------------------
films <- tibble()
for (i in seq_len(nrow(dat))) {
tmp <- dat$films_string[i] %>%
str_split_1(fixed(">>")) %>%
`[`(-1) %>%
str_split(fixed("~~")) %>%
map(trimws)
if (!all(map(tmp, length) == 2)) next
films <- bind_rows(
films,
tibble(
director = dat$director[i],
film = map_vec(tmp, ~ getElement(.x, 1)),
year = map_vec(tmp, ~ getElement(.x, 2))
)
)
}
# leftovers --------------------------------------------------------------------
# if it didn't find lists of two, it skipped, leaving it NA
films %>%
filter(is.na(film) | is.na(year))
dat$films_string[dat$director == "John Madden"]
## redo leftovers --------------------------------------------------------------
library(reticulate)
use_virtualenv("../../../../")
source_python("ppxai.py")
john_madden <- get_films("John Madden, the director (not the football coach)")
tmp <- john_madden %>%
str_split_1(fixed(">>")) %>%
`[`(-1) %>%
str_split(fixed("~~")) %>%
map(trimws)
films <- films %>%
na.omit() %>%
bind_rows({
tibble(
director = "John Madden",
film = map_vec(tmp, ~ getElement(.x, 1)),
year = map_vec(tmp, ~ getElement(.x, 2))
)
})
## check -----------------------------------------------------------------------
films %>%
filter(is.na(film) | is.na(year))
setdiff(dat$director, films$director)
setdiff(films$director, dat$director)
# write out --------------------------------------------------------------------
write_csv(films, "directors_films_tidy.csv")
After reading the data in, I look at each string and parse out by the
>> and ~~ delimiters I asked for. If the
list is not of length two (a film and a year), I tell it to
skip to the next iteration, since it did not parse
correctly. These will stay NA, which I investigate in the
next part of the code.
The director of Shakespeare in Love is named John Madden,
and Perplexity opted to (perhaps understandably) search for the
monocultural John Madden we all know, returning:
"John Madden did not direct any feature-length movies. His career was primarily in football as a player, coach, and broadcaster, and he is also known for his involvement in the Madden NFL video game series and various television appearances, but he did not direct any films.\n\nIf you need information on his other achievements or roles, the provided sources detail his extensive career in football and broadcasting."
So I call the model one more time, asking for the director
specifically. This got us what we needed. I write out the tidy data.
Returning fifteen random rows, it looks like:
## # A tibble: 15 × 3 ## director film year #### 1 Lee Unkrich Finding Nemo 2003 ## 2 Stanley Kubrick Full Metal Jacket 1987 ## 3 James Marsh The Mercy 2017 ## 4 Michael Cimino Heaven's Gate 1980 ## 5 Steve McQueen Widows 2018 ## 6 David Mackenzie Starred Up 2013 ## 7 Alfonso Cuarón Harry Potter and the Prisoner of Azkaban 2004 ## 8 Woody Allen Manhattan Murder Mystery 1993 ## 9 John Huston Annie 1982 ## 10 Ethan Coen The Big Lebowski 1998 ## 11 Bryan Singer X-Men 2000 ## 12 John Boorman Catch Us If You Can 1965 ## 13 Bryan Singer Valkyrie 2008 ## 14 Gus Van Sant My Own Private Idaho 1991 ## 15 Robert Zemeckis Welcome to Marwen 2018
Calculate the Feature of Interest
Remember, we don’t just want a list of films directed. For each film,
we want the number of films the director had directed before
the nominated film. The last R script does this. We have divided the
labor here by only using the LLM for what we needed: Getting us the
films. We’ve done the rest of the labor on the R side, simplifying the
prompt. In this chunk, I prep by getting: The list of actual directors
in the data, a hand-coded verification set of 110 movies, and the tidied
data.
# prep -------------------------------------------------------------------------
library(googlesheets4)
library(tidyverse)
gs4_auth()
2
# correct director
key <- read_sheet("") %>%
filter(year > 1969) %>%
mutate(film = tolower(film))
# hand-coded from last year
check <- read_csv("performance_2025.csv")
dat <- read_csv("directors_films_tidy.csv") %>%
mutate(film = tolower(film))
Then, I do some cleaning for mismatched names in the existing data
for my model versus in the data I just pulled down from Perplexity.
## hand-checked films prep -----------------------------------------------------
# are all the checks in there?
check$film[!check$film %in% dat$film]
# the post
dat$film[dat$director == "Steven Spielberg"]
dat$film[grepl("post", dat$film)] # llm missed it
# good night and good luck
dat$film[dat$director == "George Clooney"]
dat$film[dat$film == "good night, and good luck"] <- "good night and good luck"
# star wars
dat$film[dat$director == "George Lucas"]
dat$film[dat$film == "star wars: episode iv - a new hope"] <- "star wars"
# mash
dat$film[dat$director == "Robert Altman"]
dat$film[dat$film == "m*a*s*h"] <- "mash"
# la confidential
dat$film[dat$film == "l.a. confidential"] <- "la confidential"
# precious
dat$film[grepl("precious: ", dat$film)] <- "precious"
# once upon a time in hollywood
dat$film[dat$director == "Quentin Tarantino"]
dat$film[
dat$film == "once upon a time... in hollywood"
] <- "once upon a time in hollywood"
check <- check %>%
filter(film %in% dat$film)
Then I parse the year by getting the first four digits of the year
column and coercing to numeric.
## auto parse year ------------------------------------------------------------- dat <- dat %>% mutate(year = as.numeric(str_sub(year, 1, 4))) %>% filter(!is.na(year))
And here is the workhorse block:
# calculate lookback -----------------------------------------------------------
check$from_llm <- NA
for (i in check$film) {
directors <- key %>%
filter(film == i) %>%
pull(director) %>%
str_split_1(fixed(", "))
check$from_llm[check$film == i] <- map(
directors,
~ {
tryCatch(
dat %>%
filter(director == .x) %>%
arrange(year) %>%
filter(year < year[film == i]) %>%
nrow(),
error = function(e) NA,
warning = function(w) NA
)
}
) %>%
unlist() %>%
mean(na.rm = TRUE)
}
For each film in the hand-checked dataset, I map()
through the directors (since there could have been multiple) and count
the number of entries before the year that the film of interest was
released. You’ll see I do a mean() call at the end, such
that if there were multiple directors, I use the mean of them.
I also return NA upon any error or warning. The only time this popped
up was for Adam McKay. The model was a bit too detailed and
returned two lists:
">> Anchorman: The Legend of Ron Burgundy ~~ 2004\n>> Anchorman 2: The Legend Continues ~~ 2013\n>> Talladega Nights: The Ballad of Ricky Bobby ~~ 2006\n>> Step Brothers ~~ 2008\n>> The Other Guys ~~ 2010\n>> The Big Short ~~ 2015\n>> Vice ~~ 2018\n>> Don't Look Up ~~ 2021\n>> We the Economy: 20 Short Films You Can't Afford to Miss (segment \"The Unbelievably Sweet Alpacas\") ~~ 2014\n\nNote: While \"We the Economy: 20 Short Films You Can't Afford to Miss\" is a collection of short films, the specific segment directed by Adam McKay is included here as it is part of his feature-length filmography in the context of directing. However, if strictly adhering to feature-length films only, this entry could be excluded.\n\nUpdated list without the short film segment:\n\n>> Anchorman: The Legend of Ron Burgundy ~~ 2004\n>> Anchorman 2: The Legend Continues ~~ 2013\n>> Talladega Nights: The Ballad of Ricky Bobby ~~ 2006\n>> Step Brothers ~~ 2008\n>> The Other Guys ~~ 2010\n>> The Big Short ~~ 2015\n>> Vice ~~ 2018\n>> Don't Look Up ~~ 2021"
It tells us some reasoning, even though we didn’t ask for it: There
is a feature-length film where Adam McKay directed a short film within
it. The model gave us two possible lists. We’re going to clean it by
taking the second list, which excludes the collection of short
films:
# failures ---------------------------------------------------------------------
check %>%
filter(is.na(from_llm))
directors <- key %>%
filter(film == "vice") %>%
pull(director) %>%
str_split_1(fixed(", "))
read_csv("directors_films.csv") %>%
filter(director == directors) %>%
pull(films_string)
check$from_llm[check$film == "vice"] <- dat %>%
filter(director == directors) %>%
arrange(year) %>%
unique() %>% # dedupe
filter(!grepl("economy", film)) %>% # get rid of short film collection
filter(year < year[film == "vice"]) %>%
nrow()
# make sure empty
check %>%
filter(is.na(from_llm))
Now we’ve got a clean verification set. It is 110 movies, with
columns for:
-
Hand-checked number of films directed before the film of
interest -
Perplexity-based estimate
-
Estimate from previous post, using GPT-3.5 Turbo and
LangChain
Fifteen random entries from these data look like:
## # A tibble: 15 × 5 ## year film check last_post from_llm #### 1 1978 midnight express 1 3 1 ## 2 1971 nicholas and alexandra 7 2 6 ## 3 2016 manchester by the sea 2 1 2 ## 4 2018 blackkklansman 22 21 22 ## 5 1983 terms of endearment 0 2 0 ## 6 1993 in the name of the father 2 2 2 ## 7 2013 12 years a slave 2 2 2 ## 8 2015 the revenant 5 5 5 ## 9 2009 the blind side 3 2 3 ## 10 1970 mash 3 3 5 ## 11 2007 atonement 1 1 1 ## 12 1985 prizzi's honor 37 35 36 ## 13 1977 the turning point 8 5 8 ## 14 2001 the lord of the rings: the fellowship of the … 5 5 5 ## 15 2003 lost in translation 1 1 1
Let’s see how we did.
Performance
First, let’s compare: the correlation; mean absolute error (MAE); and
how often we were correct, overcounted, or undercounted. Let’s do this
first for Perplexity:
# performance ------------------------------------------------------------------ cor.test( ~ check + from_llm, check) ## ## Pearson's product-moment correlation ## ## data: check and from_llm ## t = 60.394, df = 108, p-value < 2.2e-16 ## alternative hypothesis: true correlation is not equal to 0 ## 95 percent confidence interval: ## 0.9789129 0.9900619 ## sample estimates: ## cor ## 0.9855161 check %>% summarise(mae = mean(abs(check - from_llm))) ## # A tibble: 1 × 1 ## mae #### 1 0.5 check %>% mutate(err_disc = case_when( (check - from_llm) > 0 ~ "Undercount", (check - from_llm) < 0 ~ "Overcount", (check - from_llm) == 0 ~ "Correct" )) %>% count(err_disc) %>% mutate(pct = n / sum(n) * 100) ## # A tibble: 3 × 3 ## err_disc n pct ## ## 1 Correct 77 70 ## 2 Overcount 18 16.4 ## 3 Undercount 15 13.6
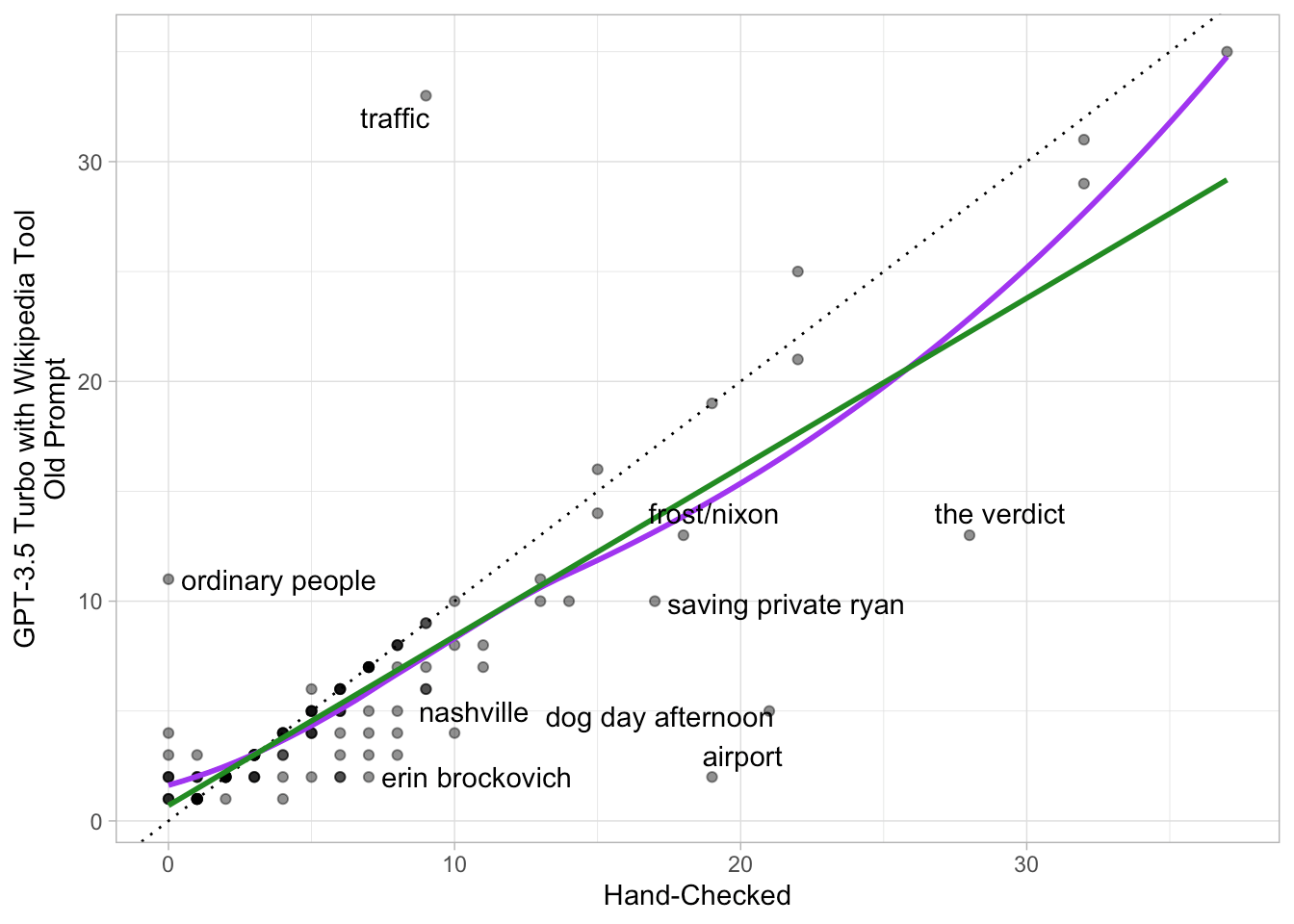
Versus last time (GPT-3.5 Turbo with Wikipedia Tool):
## compare to last time -------------------------------------------------------- cor.test( ~ check + last_post, check) ## ## Pearson's product-moment correlation ## ## data: check and last_post ## t = 15.007, df = 108, p-value < 2.2e-16 ## alternative hypothesis: true correlation is not equal to 0 ## 95 percent confidence interval: ## 0.7503941 0.8747150 ## sample estimates: ## cor ## 0.8221232 check %>% summarise(mae = mean(abs(check - last_post))) ## # A tibble: 1 × 1 ## mae #### 1 2.01 check %>% mutate(err_disc = case_when( (check - last_post) > 0 ~ "Undercount", (check - last_post) < 0 ~ "Overcount", (check - last_post) == 0 ~ "Correct" )) %>% count(err_disc) %>% mutate(pct = n / sum(n) * 100) ## # A tibble: 3 × 3 ## err_disc n pct ## ## 1 Correct 46 41.8 ## 2 Overcount 17 15.5 ## 3 Undercount 47 42.7
We’ve made tremendous improvements here:
-
Correlation between estimate vs. truth increases from r
= .82 last time to r = .99 this time. -
MAE decreases from 2.01 films to 0.50 films.
-
We go from a correct count 42% of the time to a correct count 70%
of the time. -
Undercounting (14%) and overcounting (16%) are now happening at
about the same rate, while beforehand we were much more likely to
undercount (43%) then to overcount (16%).
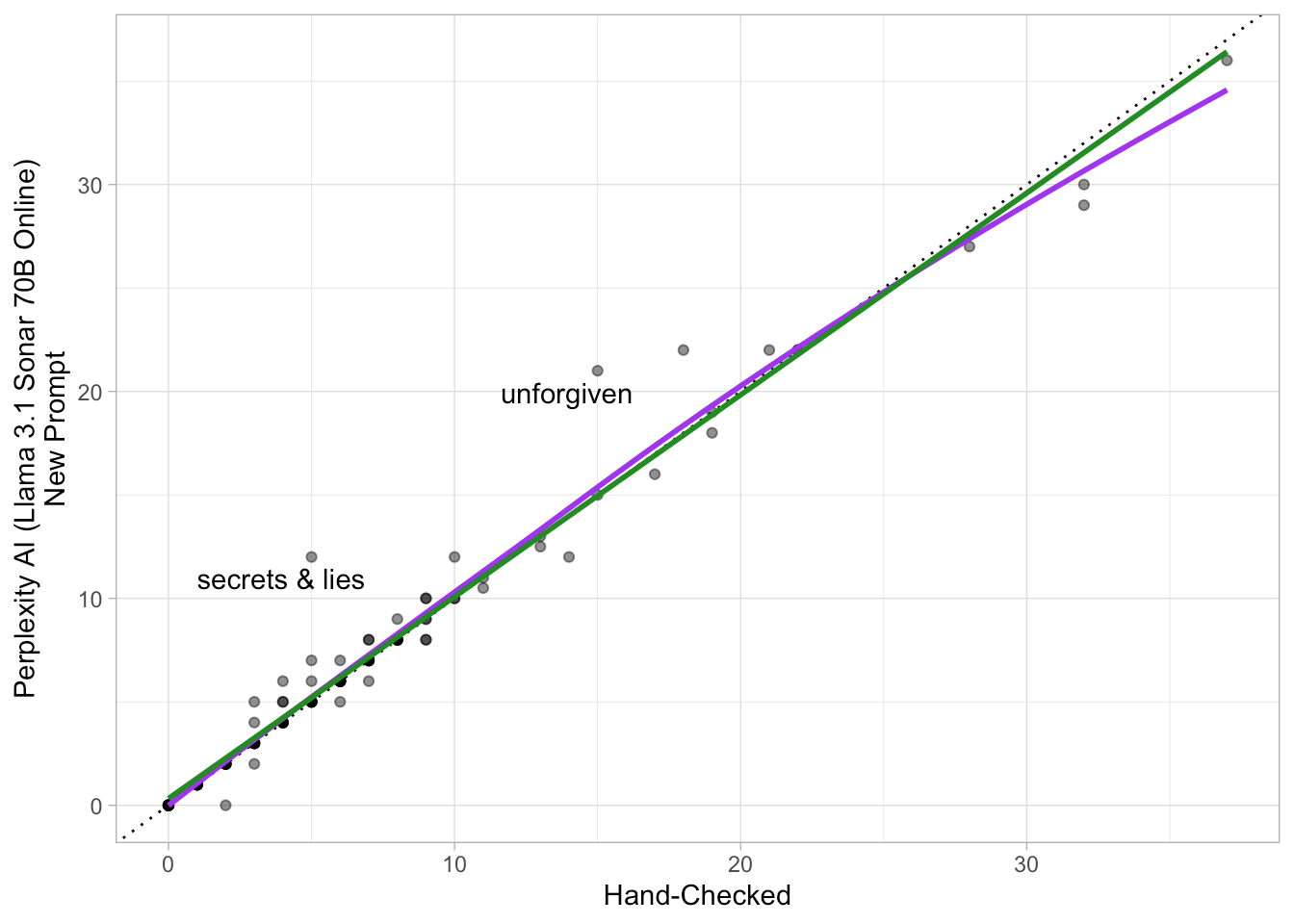
Lastly, let’s plot the true, hand-checked number on the x-axis versus
the estimated number on the y-axis. The purple line is a loess, the
green line is OLS, and the dotted black line is a perfect relationship.
I label any data point where the absolute error was five or more films
off.
ggplot(check, aes(x = check, y = from_llm)) +
geom_abline(aes(intercept = 0, slope = 1), linetype = "dotted") +
geom_point(alpha = .5) +
geom_smooth(method = "loess", se = FALSE, span = .95, color = "purple") +
geom_smooth(method = "lm", se = FALSE, color = "forestgreen") +
theme_light() +
labs(
x = "Hand-Checked",
y = "Perplexity AI (Llama 3.1 Sonar 70B Online)\nNew Prompt"
) +
ggrepel::geom_text_repel(
aes(label = ifelse(abs(check - from_llm) >= 5, film, ""))
)
![]()
ggplot(check, aes(x = check, y = last_post)) +
geom_abline(aes(intercept = 0, slope = 1), linetype = "dotted") +
geom_point(alpha = .5) +
geom_smooth(method = "loess", se = FALSE, span = .95, color = "purple") +
geom_smooth(method = "lm", se = FALSE, color = "forestgreen") +
theme_light() +
labs(
x = "Hand-Checked",
y = "GPT-3.5 Turbo with Wikipedia Tool\nOld Prompt"
) +
ggrepel::geom_text_repel(
aes(label = ifelse(abs(check - last_post) >= 5, film, ""))
)
![]()
This time, the only two notable misses were for Secrets &
Lies by Mike Leigh and Unforgiven by Clint Eastwood.
Looking at Mike Leigh, Perplexity picked up on stage plays he
directed, which I did not mention in the prompt. As for Clint Eastwood,
it picked up a few acting credits—but not all of them.
Conclusion
I revisited an earlier post and greatly improved my ability to
extract information using an LLM by:
-
Employing a service—Perplexity AI—that incorporates web search
for me -
Breaking up the task into smaller parts and dividing the labor,
only relying on the LLM when necessary -
Re-writing my prompt in line with best practices and key
principles—as well as relying on few-shot learning
All of this underscores the importance of prompt engineering and how
understanding the architecture of an LLM can lead to querying one
better. Remember that, even with more complex models that can call tools
be somewhat agentic, these are all just machines that do next-token
prediction. Berryman
& Zeigler provide a good way of thinking while you’re writing
prompts: “Don’t ask yourself how a reasonable person would ‘reply’ …but
rather how a document that happens to start with the prompt might
continue” (pg. 18).
Related



{kind=link}