

Want to share your content on R-bloggers? click here if you have a blog, or here if you don’t.
Introduction
In last week’s article, we covered how you can interact with a local language model from R, using LM Studio and the Phi-3 model. Although local language models have the advantage of not incurring any costs asides from your electricity bills, they are likely to be less powerful than the more complex large language models (LLMs) that are hosted on cloud. There are many ways to interact with different LLMs from R, and one of them is through Azure OpenAI, which is the method that I will cover here. Azure OpenAI services allows you access to models from OpenAI such as GPT-4o, DALL·E, and more.
In this post, we will cover:
- how to set up an Azure OpenAI deployment
- how to use {keyring} to avoid exposing your API key in your R code
- an example on creating a prompt function to connect to Azure OpenAI
- using {rvest} to extract text content from websites for summarisation
For demo purposes, we will use the same 100 climbs dataset that we had used as an example last week. The goal of our exercise here is to summarise a website’s content based on a URL, using only R and an Azure subscription.
![]()

Why use Azure OpenAI instead of OpenAI?
One clear alternative is to access the OpenAI APIs directly through OpenAI’s platform. However, using Azure OpenAI offers several advantages. It allows for seamless integration with other Azure services you may already use, such as Azure Key Vault, and enables you to manage related projects under the same subscription or resource group. Additionally, while OpenAI’s services are currently inaccessible in Hong Kong, Azure OpenAI remains available (at the time of writing).
Setting Up Azure OpenAI
1. Subscription, resource group, and resource
To begin leveraging Azure OpenAI for web content summarization, you’ll first need to sign up for an account on Azure. Once you have set up an account, you will need to:
- Create a subscription – a billing unit to manage costs and track usage
- Create a resource group for your project – for organising resources
- Create an Azure OpenAI resource
All of these can be accessed easily by typing into the search bar at the top of the Azure portal.
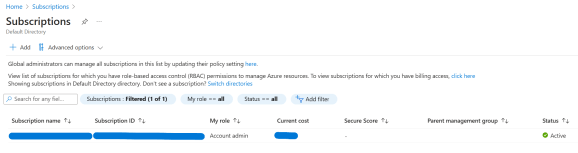
When you go into Subscriptions, this is what you will see. Click ‘Add’ to add a subscription:
![]()
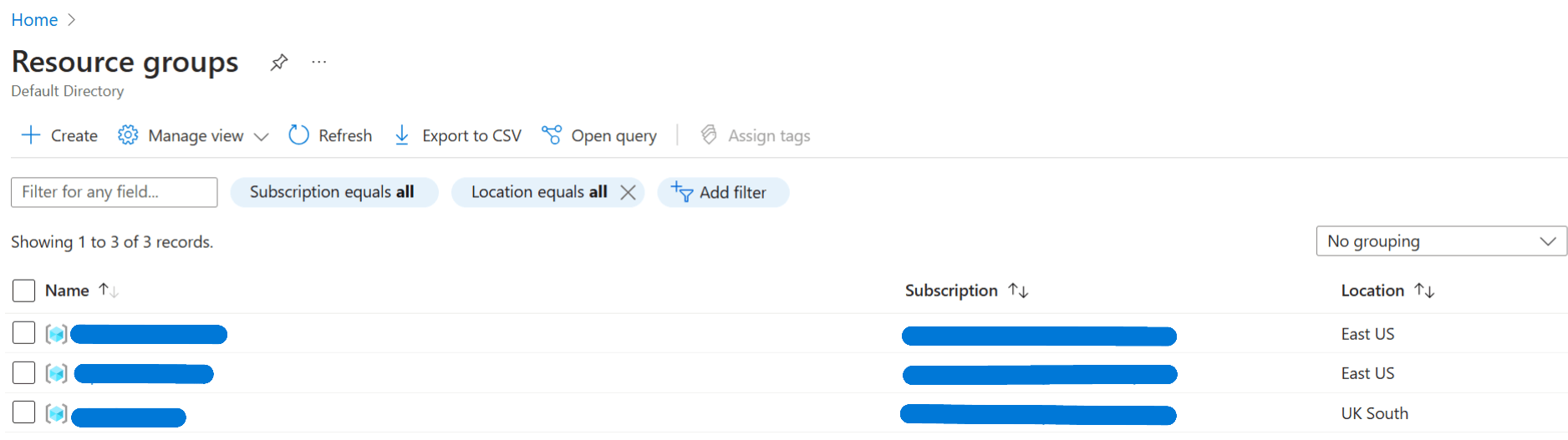
You should then create a resource group that is linked to the relevant subscription. You can read more here to decide on whether you should create new resource groups if you have other related projects on Azure:
![]()
Next, go to Azure OpenAI account under Azure AI services to create an Azure OpenAI resource:
![]()

To create the resource, you will need to supply information such as subscription, resource group, and details on the instance that you wish to create:
![]()

For simplicity, we will select ‘All networks’ for this example. Other options provide more secure methods to set up this workflow:
![]()

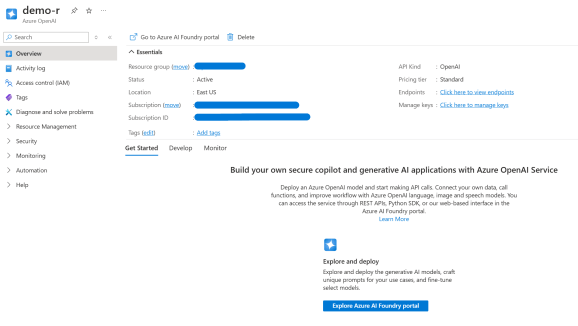
This should be what you see when you go to Azure OpenAI. In this example, we have called our resource ‘demo-r’:
![]()
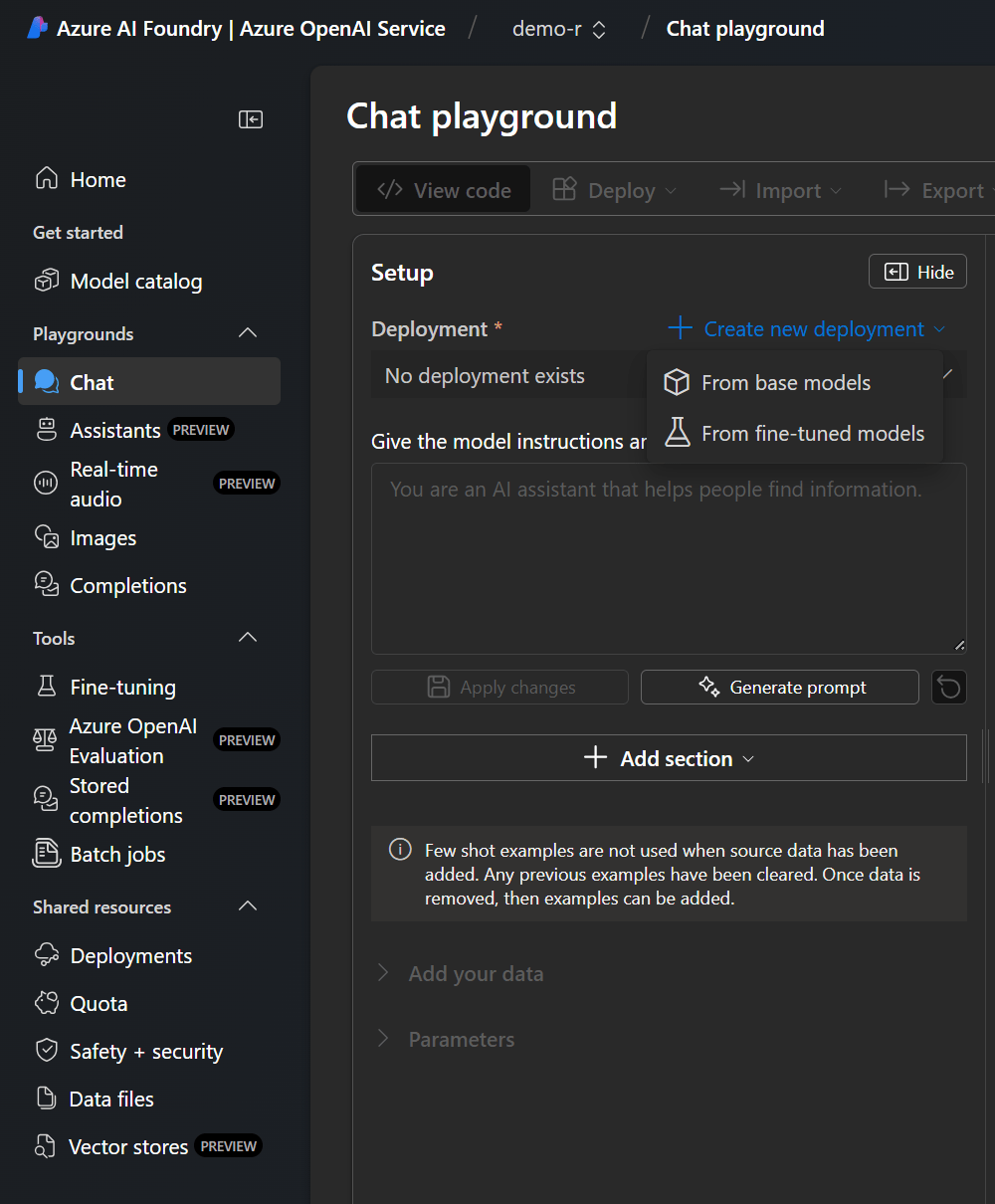
2. Set up deployment
Once you have your subscription, resource group, and Azure OpenAI resource, the next step is to go to Azure AI Foundry portal and create a new deployment ‘From base models’. We can start with ‘gpt-4o-mini’, as this is one of the cheapest models available and allows us to experiment without breaking the bank:
![]()
Once you have created your deployment, use the left side bar and navigate to ‘Shared Resources > Deployments’. Click on your deployment, and you will find your API key and Azure Open AI Endpoint here. These are the two key bits of information that you need, and you should store these in a safe place (not in code!).
![]()

3. Storing your API key in {keyring}
You must never expose your API key / secret directly in your code – the worst case scenario is you accidentially pushing your key to GitHub and your API key becoming accessible to everyone. The {keyring} package in R helps with this problem by enabling you to store and retrieve your keys easily, using your operating system’s credential store that is more secure than storing secrets in environment variables.
Running keyring::key_set() triggers a dialogue box where you can save your API key, which you can link to a service (“openai_api”):
library(keyring)
key_set("openai_api")

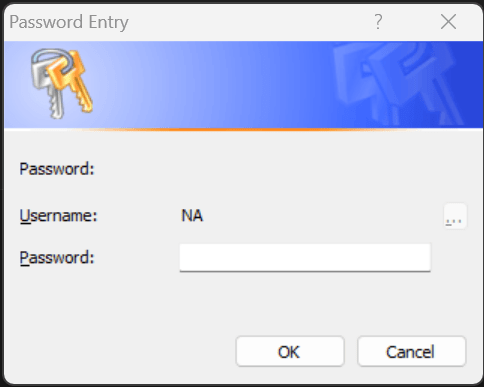
You can then retrieve the key by running key_get():
key_get("openai_api")
Once a secret is defined, the “keyring” persists across multiple R sessions. I would definitely recommend checking out the {keyring} documentation for more information on how it works and on other options on improving security.
Scraping the source data with rvest
In this section, I will show you how to extract a source article from a URL that we can use for summarisation with our LLM.
1. Accessing Example Dataset
Let us start by loading the required packages in R:
library(tidyverse) library(rvest) library(keyring) library(httr) library(jsonlite)
You can load the Top 100 Climbs dataset and extract relevant URLs using the following code snippet:
# Reading the dataset top_100_climbs_df <- read_csv( "https://raw.githubusercontent.com/martinctc/blog/refs/heads/master/datasets/top_100_climbs.csv" ) urls <- top_100_climbs_df$url urls
This is what urls returns:
> top_100_climbs_df$url [1] "https://cyclinguphill.com/cheddar-gorge/" [2] "https://cyclinguphill.com/100-climbs/weston-hill-bath/" [3] "https://cyclinguphill.com/100-climbs/crowcombe-combe/" [4] "https://cyclinguphill.com/porlock-hill-climb/" [5] "https://cyclinguphill.com/100-climbs/dunkery-beacon/" [6] "https://cyclinguphill.com/100-climbs/exmoor-forest-climb/" [7] "https://cyclinguphill.com/100-climbs/challacombe/" [8] "https://cyclinguphill.com/100-climbs/dartmeet-climb/" [9] "https://cyclinguphill.com/100-climbs/haytor-vale/" [10] "https://cyclinguphill.com/100-climbs/widecombe-hill/"
For this demo, let us just use the first URL here for our summarisation task:
> urls[[1]] [1] "https://cyclinguphill.com/cheddar-gorge/"
The rvest package (which is part of tidyverse) is a powerful package for scraping web content. Previously, I’ve written a short example on how to scrape reviews from Amazon using the same package.
In our example, what we want to do is to extract the relevant content from the Cheddar Gorge climbs page, based on the URL. This is the code that I have used:
library(rvest)
# Use rvest to extract content from URL
page_content <- read_html(urls[[1]])
# Parse page_content to extract the text
page_text <- page_content %>% html_elements(".entry-content") %>% html_text()
Looking at the page source of the Cheddar Gorge website, I could skim that entry-content is the div class that best matches onto the ‘real’ content that concerns the Cheddar Gorge climb, which is why I used html_elements(".entry-content") to identify that specific part of the page content.
Here is a snippet of what is captured in page_text:
[1] "\n\t\t\tCheddar Gorge is an interesting climb through the beautiful limestone gorge of Cheddar, Somerset. Climbing gently out of the village of Cheddar, the road starts to snake upwards at a gradient of up to 16% round some twisty corners. It is a tough start to the climb, but the remaining couple of km are a much gentler gradient, allowing you the opportunity to take it at your own pace as you climb away from the gorge and onto to the top of the moor.\n\nCheddar Gorge full hill\nLocation: Cheddar, Mendip hills, Somerset, South West.\nDistance 2.6 miles\nAverage gradient: 4-5%\nMaximum gradient: 16%\nHeight gain. 150m\n100 climbs: #1\nCheddar Gorge, Strava\nCheddar Gorge understandably features in many local cyclo-sportives and is a popular destination for many cyclists. It is also popular with tourists and rock climbers. The road can be busy – especially as you leave the village of Cheddar...
Now that we have our target content for summarisation stored in page_text, we can start setting up the function to interact with OpenAI.
Interacting with OpenAI
1. Gathering all the pieces
There are four key pieces that we need to interact with Azure OpenAI from R:
- Azure OpenAI key
- API endpoint
- System prompt
- User prompt
We already have (1) and (2) identified in the earlier section:
# Get the API key from the keyring
az_key <- keyring::key_get("openai_api")
# Assign chat completions endpoint to variable
azo_completions_ep <- paste0(
az_openai_endpoint,
"openai/deployments/",
"gpt-4o-mini/chat/completions?api-version=2024-08-01-preview"
)
As for the prompts, we can use page_text as the user prompt, and for the system prompt write something similar like the below to start:
# Set system prompt sys_prompt <- "Please summarise the following article, identifying the top 3-5 takeaways."
2. Writing a Custom Function
Now that we have all the pieces together, we can put together the interaction function to generate the chat completions:
generate_completion <- function(
sys_prompt,
user_prompt,
api_endpoint = azo_completions_ep,
api_key = az_key) {
response <- POST(
url = api_endpoint,
add_headers(
"api-key" = api_key
),
body = list(
messages = list(
list(role = "system", content = sys_prompt),
list(role = "user", content = user_prompt)
),
max_tokens = 1000,
temperature = 0.7,
top_p = 1
),
encode = "json"
)
response_content <- content(response, as = "parsed", type = "application/json")
response_text <- response_content$choices[[1]]$message$content
# Calculate token count
token_count <- (nchar(sys_prompt) + nchar(user_prompt)) / 4 # Rough estimate of tokens
return(tibble(
prompt = user_prompt,
response = response_text,
token_count = token_count
))
}
The generate_completion function above sends a request to the Azure OpenAI endpoint to generate a completion (a summary) based on the system prompt and user prompt we provided. A data frame / tibble is returned, containing a column for:
prompt: the original user prompt (source text for Cheddar Gorge)response: the summary returned by the LLMtoken_count: a count of the number of tokens used in the prompt
You can always adapt the function to only return the response, but I usually prefer to have metadata readily available and stored in a tidy data frame / tibble. This also makes it easier as you scale out the script to run it across a list of inputs.
Note that the above function does not contain any mechanisms for handling retries (for when there are rate limits, or server errors) and for handling unsuccessful responses (anything that isn’t HTTP 200). This could make it difficult to debug when there is a problem with say the format of the HTTP request, or when trying to scale this out to summarising multiple texts. For reference, here are some common HTTP responses you can get:
| Status Code | Description |
|---|---|
| 200 | OK |
| 201 | Created |
| 204 | No Content |
| 301 | Moved Permanently |
| 302 | Found |
| 400 | Bad Request |
| 401 | Unauthorized |
| 403 | Forbidden |
| 404 | Not Found |
| 429 | Too Many Requests |
| 500 | Internal Server Error |
| 502 | Bad Gateway |
| 503 | Service Unavailable |
To include a retry mechanism and response handling, this is how generate_completion() can be enhanced:
generate_completion <- function(
sys_prompt,
user_prompt,
api_endpoint = azo_completions_ep,
api_key = az_key,
max_retries = 5) {
retries <- 0
while (retries < max_retries) {
response <- POST(
url = api_endpoint,
add_headers(
"api-key" = api_key
),
body = list(
messages = list(
list(role = "system", content = sys_prompt),
list(role = "user", content = user_prompt)
),
max_tokens = 1000,
temperature = 0.7,
top_p = 1
),
encode = "json"
)
if (status_code(response) == 200) {
response_content <- content(response, as = "parsed", type = "application/json")
response_text <- response_content$choices[[1]]$message$content
# Calculate token count
token_count <- (nchar(sys_prompt) + nchar(user_prompt)) / 4 # Rough estimate of tokens
return(tibble(
prompt = user_prompt,
response = response_text,
token_count = token_count
))
} else if (status_code(response) == 429) {
# Handle 429 error by waiting and retrying
retry_after <- as.numeric(headers(response)$`retry-after`)
if (is.na(retry_after)) {
retry_after <- 2 ^ retries # Exponential backoff
}
Sys.sleep(retry_after)
retries <- retries + 1
} else {
warning(paste("Error in API request:", status_code(response)))
retries <- retries + 1
Sys.sleep(2 ^ retries) # Exponential backoff for other errors
}
}
stop("Max retries exceeded")
}
To generate the summary completion, you can run this:
output_df <-
generate_completion(
sys_prompt = sys_prompt,
user_prompt = page_text,
max_retries = 1
)
output_df
… which returns the following tibble:
> output_df # A tibble: 1 × 3 prompt response token_count1 "\n\t\t\tCheddar Gorge is an interesting climb through t… "**Summ… 1004.
3. Final Summary
I’m sure you are keen to see what our LLM has summarised! Here is what’s returned from output_df$response:
Summary of Cheddar Gorge Climb Article:
Cheddar Gorge is a notable cycling climb located in Somerset, England, characterized by its picturesque limestone landscape and challenging gradients. The climb features a steep initial section followed by a gentler ascent, making it a popular choice for cyclists and tourists alike.
Top Takeaways:
-
Climbing Details: The climb spans 2.6 miles with an average gradient of 4-5% and a maximum gradient of 16%, resulting in a height gain of 150 meters. The steepest section is located at the base, near the car parks.
-
Popularity: Cheddar Gorge is frequently included in local cyclo-sportives and is a favored spot for both cyclists and rock climbers. It also attracts tourists, making the road busy, especially near the village.
-
Historical Significance: The gorge hosted the 2007 National Hill Climb Championship, showcasing competitive cycling talent and providing a challenging venue for participants.
-
Scenic Experience: The climb offers stunning views and a twisting descent, but caution is advised due to sharp corners that can lead to high speeds.
-
Local Attractions: Cheddar Gorge is part of the Mendip hills, which offers other climbing opportunities like Burrington Combe, enhancing the area’s appeal for cycling enthusiasts.
Pretty cool, right? You can also easily scale this out using purrr, running generate_completion() through all the content extracted from each URL in urls.
For those wanting to test out a simpler example of interacting with Azure OpenAI without using rvest, you can also try this mini snippet:
generate_completion( sys_prompt = "Describe the following animal in terms of its taxonomic rank, habitat, and diet.", user_prompt = "yellow spotted lizard", max_retries = 1 )
Where the response gives…
The yellow spotted lizard, scientifically known as Eulimastoma gracile, belongs to the following taxonomic ranks:
- Domain: Eukarya
- Kingdom: Animalia
- Phylum: Chordata
- Class: Reptilia
- Order: Squamata
- Family: Teiidae
- Genus: Eulimastoma
- Species: Eulimastoma gracile
Habitat: The yellow spotted lizard is typically found in arid and semi-arid regions, including deserts and scrublands. It prefers areas with loose soil and ample cover, such as rocks, vegetation, and debris, which provide shelter and hunting grounds.
Diet: This lizard is primarily insectivorous, feeding on a variety of insects and other small invertebrates. It may also consume small vertebrates and plant matter occasionally, depending on the availability of food sources in its habitat.

Conclusion
In this blog, we explored the steps to summarize web content utilizing Azure OpenAI’s capabilities, interacting with the gpt-4o-mini model from R. I would love to hear from the comments below if you have found any interesting applications for this, and if you have any suggestions / thoughts on the code!
Related


{kind=link}