
A skeet floated across my Bluesky feed that looked at the cross-sectional relationship between incidence of depression in 2020 and voting for Trump in the 2024 Presidential election. The data in the skeet and immediate blog post was at state level, but the hypothesis of interest in an article that sparked all this was an individual one (are depressed people voting for Trump). I don’t have the individual level microdata that might help explore the actual hypothesis, but I was surprised to see that the state-level regression had a significant evidence of an effect, and wondered if this would continue at the county level, which still has relatively accessible data.
This also led me down an interesting but familiar rabbit hole of multilevel modelling in the presence of a spatial correlation nuisance.
Ordinary Least Squares
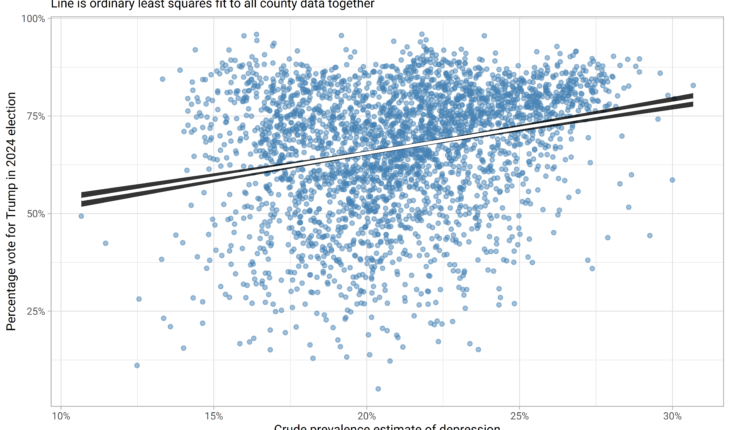
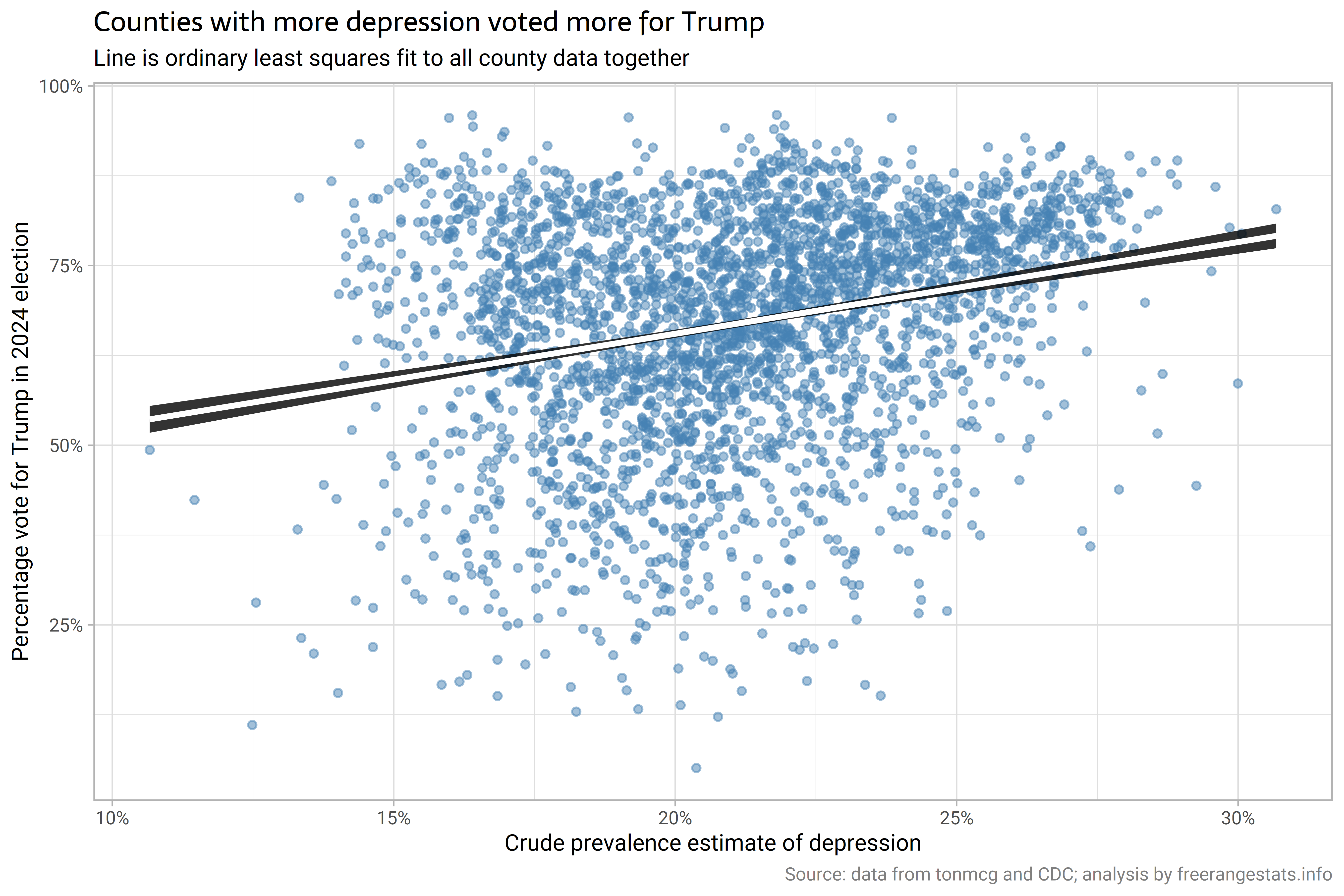
Well, it turns out depression at the county level does correlate with voting for Trump, as we can see with this first, simple chart which shows the expected vote based on a model fit with ordinary least squares (OLS):
I’ll be fitting some more fancy models and getting better charts further down, but the basic message is the same as in this one – counties with higher incidence of depression had a higher proportion of their vote going to Trump than was the case with counties with lower levels of depression.
Before I say anything else or show any code, let’s get straight that this is very possibly not a causal link. In fact there are at least three things that are plausibly happening here:
- People who are more depressed were more likely to vote for Trump (or less likely to turn up to vote against him, which given voluntary voting, has a similar result although for importantly different reasons)
- People (who may themselves be not depressed) who are in areas with lots of depressed people around them were more likely to vote for Trump (eg because voters think “Trump will be able to do something about all the depressed people around here”)
- Some underlying factor (eg economic, social or cultural conditions) that leads to some areas having higher rates of depression also leads to higher votes for Trump, through some other mechanism
My expectation is that #3 is the more likely explanation, but I personally don’t actually have evidence to choose between them. Nor are these hypotheses mutually exclusive; two or all of them might be true at once.
OK here’s the code that gets that data and produces the first chart and a simple model with a statistically significant effect:
library(tidyverse)
library(readxl)
library(mgcv)
library(lme4)
library(sf)
# county level prevalence of depression at (have to hit the 'download' button)
# https://stacks.cdc.gov/view/cdc/129404
dep <- read_excel("cdc_129404_DS1.xlsx", skip = 1)
fn <- "2024_US_County_Level_Presidential_Results.csv"
if(!file.exists(fn)){
download.file("https://raw.githubusercontent.com/tonmcg/US_County_Level_Election_Results_08-24/refs/heads/master/2024_US_County_Level_Presidential_Results.csv",
destfile = fn)
}
votes <- read_csv("2024_US_County_Level_Presidential_Results.csv")
combined <- votes |>
inner_join(dep, by = c("county_fips" = "CountyFIPS code")) |>
mutate(cpe = `Crude Prevalence Estimate` / 100,
aape = `Age-adjusted Prevalence Estimate` / 100)
# what was missed in this join?
votes |>
anti_join(dep, by = c("county_fips" = "CountyFIPS code")) |>
count(state_name)
# 37 counties in Alaska, 9 and Connecticut and 7 in DC. Will ignore these
# for my purposes.
#========================modelling==================
#----------Ordinary Least Squares------------------
model <- lm(per_gop ~ cpe, data = combined)
summary(model)
# note several things could be happening here:
# - depressed people makes you vote for Trump
# - being around depressed people makes you vote for Trump
# - some underlying condition (eg economic) both leads to higher depression
# and more likely to vote for Trump. This seems the most likely.
the_caption = "Source: data from tonmcg and CDC; analysis by freerangestats.info"
# draw chart:
combined |>
ggplot(aes(x= cpe, y = per_gop)) +
geom_point(colour = "steelblue", alpha = 0.5) +
geom_smooth(method = "lm", fill = "black", colour = "white", alpha = 0.8) +
scale_x_continuous(label = percent) +
scale_y_continuous(label = percent) +
labs(x = "Crude prevalence estimate of depression",
y = "Percentage vote for Trump in 2024 election",
subtitle = "Line is ordinary least squares fit to all county data together",
title = "Counties with more depression voted more for Trump",
caption = the_caption)
Excerpt from the results:
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.40002 0.01861 21.49 <2e-16 ***
cpe 1.27547 0.08712 14.64 <2e-16 ***
Generalized linear model with a quasibinomial response
Now, I wanted to improve this for all sorts of reasons, although I suspected it was actually good enough for pragmatic purposes – case proven really, that counties with more depressed people voted more for Trump. Proven enough to justify the further work with additional data needed to explore why. But I had some statistical loose ends to tidy up. First of which is that vote is a proportion, and it feels icky to use OLS (which can send values above 1 and below 0) to model a proportion when we have generalized linear models (GLMs) designed for the job and easily available.
I didn’t want to use a straight logistic regression because the county-level data is far more dispersed than would be expected if it really were individuals making their own voting decisions. But a GLM with a quasi-binomial response keeps the link function used in logistic regression and the relationship of the mean and variance, while allowing the variance to be larger (or smaller) by some consistent ratio. Here’s what I get with that GLM:
…created with this code. Note that we now have started to weight counties based on their overall number of voters, which makes particular sense for a binomial or similar family response. I suspect this is one of the key issues driving the line vertically down, compared to the OLS version. The other key difference of course is that now it is slightly curved, as the ‘linear’ in a GLM is on the link scale, not the scale the response is originally observed on and used for this chart.
#----------------Quasibinomial GLM----------------
model2 <- glm(per_gop ~ cpe,
family = quasibinomial, data = combined, weights = total_votes)
summary(model2)
preds2 <- predict(model2, type = "response", se.fit = TRUE)
# draw chart:
combined |>
mutate(fit = preds2$fit,
se = preds2$se.fit,
lower = fit - 1.96 * se,
upper = fit + 1.96 * se) |>
ggplot(aes(x = cpe, y = per_gop)) +
geom_point(colour = "steelblue", alpha = 0.5) +
geom_ribbon(aes(ymin = lower, ymax = upper), fill = "black", alpha = 0.5) +
geom_line(aes(y = fit), colour = "white") +
theme(legend.position = "none") +
scale_y_continuous(limits = c(0, 1), label = percent) +
scale_x_continuous(label = percent) +
labs(x = "Crude prevalence estimate of depression",
y = "Percentage vote for Trump in 2024 election",
subtitle = "Line is generalized linear model with quasibinomial response, fit to all county data together",
title = "Counties with more depression voted more for Trump",
caption = the_caption)
Here’s an excerpt from that summary of model2:
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -1.82178 0.06823 -26.70 <2e-16 ***
cpe 9.25748 0.34153 27.11 <2e-16 ***
We see cpe (crude prevalence estimate, ie not the age-standardised one) has very definitely “significant” evidence that it isn’t zero, with a point estimate of 9.3 and a standard error of only 0.3.
Introducing a state effect
One thing that all the world knows is how spatially-based are US politics. Everything is thought of in terms of states, in particular, and smaller areas sometimes. It follows naturally from the ways that US politics is discussed that we should use a multi-level ie mixed-effects model with state as a random intercept, when looking at something like the overall relationship between depression and voting. In other words, we have to let the vote for Trump in any state vary for all the state-specific things that aren’t in our model, and see if after doing that we still get an overall (constant nation-wide) relationship between depression and voting in the counties within each state.
I often reach to the lme4 library by Bates, Bolker and Walker as my starting point for mixed effects models and this is the results in this case:
Note we have a bunch of parallel (on link scale) lines, one per state, with their height varying by the state random effect. I love the effect of this chart, but unfortunately lme4::glmer which is used in this case doesn’t let us use a quasibinomial family response; we have to use a binomial response which forces the variance to equal p(1-p)/n, not just be proportional to it. The net result is that the confidence intervals are much narrower than is justified.
An alternative way to fit a similar model is the the gam() function from the amazing mgcv library by Simon Wood. There’s a great discussion of this on Gavin Simpson’s blog. By specifying a spline around a categorical factor like s(state_factor, bs="re") (‘re’ stands for random effect) we can use gam() to add random intercepts while using the full range of families available to gam() including quasibinomial. That gives us this alternative version of the last model; this time with much fatter (and realistic) confidence intervals!:
The confidence intervals are now very fat. But there’s still no doubt about the significance of the evidence of the relationship of the crude prevalence of depression on voting behaviour, even after allowing a random state-level intercept.
Here’s the code for both the glmer and gam versions of this random state effect model:
#---------------------With state random effect with lmer4::glmer--------------------
model4 <- lme4::glmer(per_gop ~ cpe + (1 | state_name),
family = "binomial", data = combined,
weights = total_votes)
# note can't use quasibinomial family with glmer so we aren;t really dealing
# properly with the overdispersion. what to do about that? Confidence intervals
# will be too narrow. Various alternatives posisble.
summary(model4)
preds4 <- predict(model4, se.fit = TRUE, type = "response")
combined |>
mutate(fit = preds4$fit,
se = preds4$se.fit,
lower = fit - 1.96 * se,
upper = fit + 1.96 * se) |>
ggplot(aes(x = cpe, group = state_name)) +
geom_point(aes(y = per_gop, colour = state_name), alpha = 0.5) +
geom_ribbon(aes(ymin = lower, ymax = upper), fill = "black", alpha = 0.5) +
geom_line(aes(y = fit, colour = state_name)) +
theme(legend.position = "none") +
scale_y_continuous(limits = c(0, 1), label = percent) +
scale_x_continuous(label = percent) +
labs(x = "Crude prevalence estimate of depression",
y = "Percentage vote for Trump in 2024 election",
subtitle = "Lines are logistic regression with state-level random intercept effect (confidence intervals are too narrow)",
title = "Counties with more depression voted more for Trump",
caption = the_caption)
#--------------state random effect with mgcv::gam--------------
# gam lets us have a random effect and a wider range of families
# see https://fromthebottomoftheheap.net/2021/02/02/random-effects-in-gams/
# must be a factor to use as a random effect in gam():
combined <- mutate(combined, state_name = as.factor(state_name))
model5 <- gam(per_gop ~ cpe + s(state_name, bs="re") ,
family = quasibinomial, weights = total_votes,
data = combined)
summary(model5)
# note standard error for cpe is much higher 0.6224, compared to 0 .0107
preds5 <- predict(model5, se.fit = TRUE, type = "response")
combined |>
mutate(fit = preds5$fit,
se = preds5$se.fit,
lower = fit - 1.96 * se,
upper = fit + 1.96 * se) |>
ggplot(aes(x = cpe, group = state_name)) +
geom_point(aes(y = per_gop, colour = state_name), alpha = 0.5) +
geom_ribbon(aes(ymin = lower, ymax = upper), fill = "black", alpha = 0.5) +
geom_line(aes(y = fit, colour = state_name)) +
theme(legend.position = "none") +
scale_y_continuous(limits = c(0, 1), label = percent) +
scale_x_continuous(label = percent) +
labs(x = "Crude prevalence estimate of depression",
y = "Percentage vote for Trump in 2024 election",
subtitle = "Lines are quasibinomial generalized additive model with state-level random intercept",
title = "Counties with more depression voted more for Trump",
caption = the_caption)
Excerpt from the gam results (the better of the two, with fatter confidence intervals but still very significantly different from zero):
per_gop ~ cpe + s(state_name, bs = "re")
Parametric coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -3.2466 0.2802 -11.59 <2e-16 ***
cpe 16.3333 0.6224 26.24 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Approximate significance of smooth terms:
edf Ref.df F p-value
s(state_name) 48.44 49 20.54 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
R-sq.(adj) = 0.345 Deviance explained = 40.3%
GCV = 3333.9 Scale est. = 3387.6 n = 3107
Allowing for spatial autocorrelation
OK we’re not quite there yet. The final thing at the back of my mind is that so far, we have treated counties as though they are independent, equally valuable observations. This is pretty common in these types of cross-sectional regression, but it’s not fair; it exaggerates the value of each county data point. The values of depression and Trump vote in two adjacent counties are, frankly, not equally valuable independent observations. Once you have one, you have a good chance of predicting the values in the county next door. By failing to account for this, we are treating our data as more valuable than it is, which translates to over-confidence in our inferences and confidence intervals that are too narrow.
How to fix this? Well, there are numerous ways, but my favourite pragmatic correction is to add a fixed effect that is a sort of rubber sheet laid across the geography of interest. This can be done with gam() by including in the formula something like + s(x, y), where x and y are the centrepoints of the regions from where we have sourced observations.
Note – the other ways of correcting for this all seem to me to be way more complicated than this. Perhaps they are better! One thing I’m sure, it’s much better to do it my way than to ignore spatial autocorrelation altogether, which seems to be the near-universal approach. How often do you see an adjustment for spatial autocorrelation in a regression of US counties or states?
Now, even my pragmatic method is going to be a bother, because we need to get spatial data that isn’t available in our sources so far. The next chunk of code downloads shapefiles of all the US counties, calculates the centroids of each, and puts it into shape to join to our existing data.
#-----------gam, spatial, state effect--------------
# each county isn't really an independent data point, as counties next to eachother
# probably have lots in common. A great thing about gam is that not only can we
# have a quasibinomial family, we can do gam core business of adding in splines,
# including a two dimensional "rubber mat" that effectively knocks out our
# spatial correlation problem for us.
#
# but first we need to know the centroids of all the counties:
fn <- "cb_2023_us_county_500k.zip"
if(!file.exists(fn)){
download.file('https://www2.census.gov/geo/tiger/GENZ2023/shp/cb_2023_us_county_500k.zip',
destfile = "cb_2023_us_county_500k.zip", mode = "wb")
}
unzip(fn)
counties <- st_read("cb_2023_us_county_500k.shp")
county_cent <- counties |>
st_centroid()
sc <- st_coordinates(county_cent)
county_cent <- county_cent |>
mutate(x = sc[, 1],
y = sc[, 2],
# combine the two digit state code with the 3 digit county code:
county_fips = paste0(STATEFP, COUNTYFP))
# check that we have successfully re-created the country_fips on same basis
# as our voting and depression data:
combined |>
left_join(county_cent, by = "county_fips") |>
select(county_name, NAME)
combined2 <- combined |>
left_join(county_cent, by = "county_fips")
# check the county centres are where we expect. Note Alaska still missing
# (because voting data is not by country so lost on the first join)
ggplot(combined2, aes(x = x, y = y, colour = state_name)) +
geom_point() +
theme(legend.position = "none") +
coord_map() +
labs(title = "Centres of counties after merging data")
This gives us this plot to check that we haven’t (for example) mangled states, or latitude and longitude:
Very nice. Now we can fit the model, with this code
model6 <- gam(per_gop ~ cpe + s(x, y) + s(state_name, bs="re") ,
family = quasibinomial, weights = total_votes,
data = combined2)
# the spatial rubber mat that is correcting for spatial correlation for us;
# scheme=1 is what makes it draw a perspective plot rather than contour or
# heatmap):
plot(model6, select = 1, scheme = 1, main = "Higher vote for GOP")
That gives us this ‘rubber mat’ that I’ve included. The bit in the bottom left is Hawaii.
Basically this is going to absorb the variance that can be explained by mere proximity of one county to another. Which means that what is left to be explained by either the state random effect, or the relationship between depression and voting, is a fairer estimate.
Now, when we try to visualise this, the lines ar emuch squigglier than our previous charts. So I’ve chosen to put this into a faceted plot with a panel for each state. Here’s the end result:
… created with this code:
preds6 <- predict(model6, se.fit = TRUE, type = "response")
combined2 |>
mutate(fit = preds6$fit,
se = preds6$se.fit,
lower = fit - 1.96 * se,
upper = fit + 1.96 * se) |>
ggplot(aes(x = cpe, group = state_name)) +
geom_point(aes(y = per_gop, colour = state_name), alpha = 0.5) +
geom_ribbon(aes(ymin = lower, ymax = upper), fill = "black", alpha = 0.5) +
theme(legend.position = "none") +
scale_y_continuous(limits = c(0, 1), label = percent) +
scale_x_continuous(label = percent) +
labs(x = "Crude prevalence estimate of depression",
y = "Percentage vote for Trump in 2024 election",
subtitle = "Grey ribbons are 95% confidence intervals from quasibinomial generalized additive model with spatial effect and state-level random intercept effect",
title = "Counties with more depression voted more for Trump",
caption = the_caption) +
facet_wrap(~state_name)
Now, I think this is the best model I’ve fit to this data. The prevalence of depression (cpe) is still very much a significant (definitely non-zero) effect, and the large magnitude of this is comparable to the simpler models used so far. But we’ve got confidence that this isn’t just an artefact of the spatial closeness of counties, or of other non-included state level effects. So the extra work is worth it.
Parametric coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -2.7972 20.7488 -0.135 0.893
cpe 15.5908 0.6778 23.001 <2e-16 ***
---
Signif. codes:
0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Approximate significance of smooth terms:
edf Ref.df F p-value
s(x,y) 28.39 28.94 7.995 <2e-16 ***
s(state_name) 49.00 49.00 7.949 <2e-16 ***
That’s all folks. I guess the lesson here (not that these blogs are lessons) is really just to allow for spatial effects: both categorical ones that fit into a mixed effects / multilevel paradigm (eg random intercept at state level); and those that are more subtle spatial autocorrelation. Really, this should be done much more.
And mgcv::gam() is a great tool to address both of these at once.
Related




{kind=link}